# Use the most appropriate JSON API
Moleculer allows you to select the JSON API to use for serialization and deserialization. See this section on how to set the JSON API type. A couple of Performance tests (opens new window) were made for JSON APIs with with this test file (opens new window). There is quite a difference in speed between the various JSON and binary APIs.
Advanced — benchmark graphs (deserialization & serialization speed)
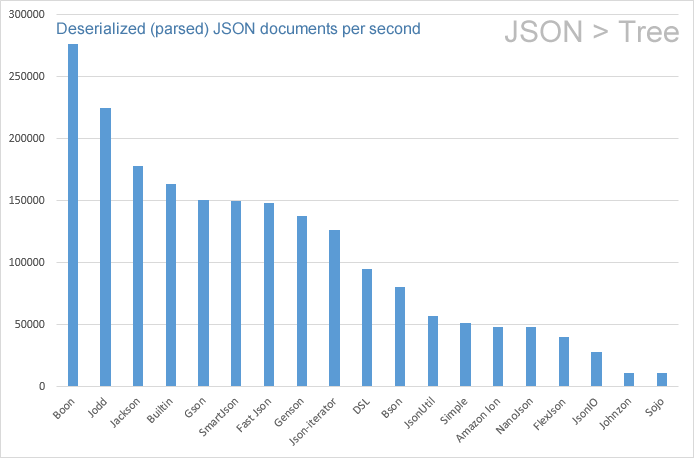
# Deserialization
The graph below shows the speed of the various JSON parsers. The vertical axis is the parsed/deserialized JSON packets per second per CPU core. A higher value means a faster parser. There is more than a 10-fold difference between the slowest and the fastest APIs. The fastest APIs are "Jodd", "Jackson" and "DSL-Json":
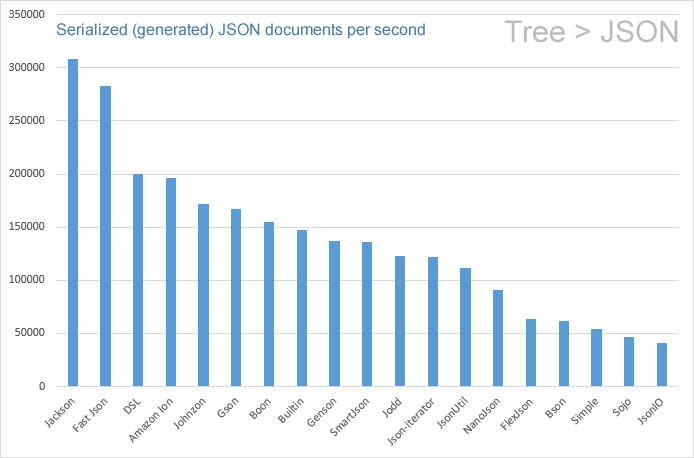
# Serialization
The graph below shows the speed of the various JSON writers. The vertical axis is the generated/serialized JSON packets per second per CPU core. A higher value means a faster generator. There is more than a 6x difference between the slowest and the fastest APIs. The fastest two APIs are "Jackson" and "DSL-Json":
Conclusion
The fastest JSON APIs are faster than most binary APIs, at least for smaller files. Among the JSON APIs, the performance of the Jackson API is outstanding when looking at the average read-write. If you want to use one JSON API, same for writing and reading, use Jackson:
ServiceBroker broker = ServiceBroker.builder()
.nodeID("server-1")
.transporter(transporter)
.readers("jackson")
.writers("jackson")
.build();
If you want to configure different JSON APIs for reading and writing, use the Jodd API for reading, and the Jackson API for writing:
ServiceBroker broker = ServiceBroker.builder()
.nodeID("server-1")
.transporter(transporter)
.readers("jodd,jackson") // Use "Jodd", fallback API is "Jackson"
.writers("jackson") // Always use "Jackson" as serializer
.build();
MessagePack serializer is a bit slower than faster JSON APIs. It makes sense to use the MessagePack serializer when sending a lot of data through streams. MessagePack can more efficiently serialize the binary contents than the JSON APIs.
Add dependencies
Remember to add the dependencies of the selected JSON API to "pom.xml" or "build.gradle".
Test the selected API
Not only are there differences in speed between JSON APIs, there is a huge difference in their knowledge. For this reason, other aspects are worth considering. This chapter just focused on speed, not capabilities.
# Thread pools
ServiceBroker uses an ExecutorService and a ScheduledExecutorService to run the tasks.
The default ExecutorService is the common ForkJoinPool.
The default ScheduledExecutorService is a ScheduledThreadPool with the same size (same number of Threads).
This setup is fast enough, but uses few Threads for some cases.
Both pool types and sizes can be configured when creating ServiceBroker, via ServiceBrokerConfig or Builder:
// Create Service Broker config
ServiceBrokerConfig cfg = new ServiceBrokerConfig();
// Set executors
cfg.setExecutor(Executors.newFixedThreadPool(8));
cfg.setScheduler(Executors.newScheduledThreadPool(4));
// Set other broker properties
cfg.setNodeID("node1");
cfg.setTransporter(...);
// Create Service Broker by config
ServiceBroker broker = new ServiceBroker(cfg);
One NioEventLoopGroup (opens new window)
can be specified for both executors (same for "Executor" and "Scheduler").
Experience has shown that an outsized pool is slower than a pool that is exactly the size of the load.
There are several graphical utilities to match the pool type and size.
One of these is
VisualVM (opens new window)
, which can accurately track the number of Threads running and their load.
Apache JMeter (opens new window)
can be used to generate the appropriate high load.
# Coding style
This chapter outlines some important Moleculer-specific coding suggestions that can affect speed or reliability.
# Collect partial results
This is a correctness rule of the Promise programming model, not just a performance tip — it is introduced in Moleculer concepts. The patterns below show how to carry several variables through a long waterfall.
The blocks of waterfall model are executed by separate Threads.
The individual "then" blocks do not reach each other's variables.
Therefore, sharing local variables between blocks would be problematic.
Fortunately, the blocks reach request-level "global" variables of the Action.
If any data in the blocks is needed later, it must be stored in this global containers.
Since these variables must be "final", we cannot use "primitive" types (int, String, etc.), only containers (eg. Tree, AtomicReference, array, map).
The following example uses a single Tree (opens new window)
object to store the processing variables of the request:
Action action = ctx -> {
// --- GLOBAL VARIABLE CONTAINER OF THE REQUEST ---
final Tree global = new Tree();
// --- WATERFALL SEQUENCE ---
return Promise.resolve().then(rsp -> {
// Executed using Thread #1
global.put("key", 123);
}).then(rsp -> {
// Executed using Thread #2
int value = global.get("key", 0);
// Create aggregated response
Tree out = new Tree();
out.put("num", value * 2);
return out;
});
};
There are other solutions besides using a single "global" Tree object.
It might be a good idea to use single-length arrays or store operation variables in multiple Atomic containers:
Action action = ctx -> {
// --- GLOBAL VARIABLE CONTAINERS OF THE REQUEST ---
// Method #1: Variables in single-length arrays
final String[] var1 = new String[1];
final Tree[] var2 = new Tree[1];
final boolean[] var3 = new boolean[1];
// Method #2: Variables in Atomic containers
final AtomicReference<Tree> var4 = new AtomicReference<>();
final AtomicLong var5 = new AtomicLong();
final AtomicBoolean var6 = new AtomicBoolean();
// --- WATERFALL SEQUENCE ---
return Promise.resolve().then(rsp -> {
// Executed using Thread #1
var1[0] = rsp.get("var1", "");
var2[0] = rsp.get("var2");
var4.set(rsp);
var5.set(rsp.get("var5", 0));
// ...
}).then(rsp -> {
// Executed using Thread #2
String val1 = var1[0];
Tree val4 = var4.get();
long val5 = var5.get();
// ...
});
};
There is no need to synchronize global variables because the execution of "then" blocks is always sequential in the waterfall logic.
# Use Trees instead of Maps
JSON APIs dynamically select which Java object to map to a JSON field during deserialization.
For example, smaller numbers arriving in JSON (eg. "1234") are usually converted to Integer.
If the number contains a decimal point, it can be Float.
If the number contains more digits, it will become Double or Long, depending on whether it contains a decimal point.
Some JSON parsers can convert larger numbers to BigInteger or BigDecimal.
The situation is similar with the JSON serializer for Date objects;
one of the JSON APIs uses the ISO 8601 format or one of the Epoch Time formats to convert Date objects to JSON.
These differences are automatically handled by the Tree API.
In the example below, the function params.get.("balance").asDouble() returns a Double in every case,
no matter what type the JSOS parser mapped to.
Either the "date" can be in Epoch Time or ISO format, each type will be a Date.
Action action = ctx -> {
// Unsafe casting, preferably DO NOT use the solution below,
// this can cause ClassCastException error at runtime
Map<String, Object> map = (Map<String, Object>) ctx.params.asObject();
double balance = (Double) map.get("balance");
Date date = dateFormat.parse((String) map.get("date"));
// Safe casting with automatic type conversion,
// this is how you get the values from "params" structure
double balance = ctx.params.get("balance").asDouble();
Date date = ctx.params.get("date").asDate();
};
# Use field name constants
Use String constants to avoid misspelled variable names.
String constants can be placed in a separate Interface so that we can refer to them from multiple Services.
The Code Completion feature of your IDE helps you complete these field names faster and more accurately.
public interface CommonFields {
// --- COMMON FIELD NAMES ---
public static final String FIELD_NAME = "name";
public static final String FIELD_AGE = "age";
public static final String FIELD_BALANCE = "balance";
public static final String FIELD_VIP = "vip";
}
At the beginning of the services you can list the names of the actions and event subscriptions.
Commonly used field names can be imported by the CommonFields interface:
public class UserService extends Service implements CommonFields {
// --- ACTION NAMES OF THIS SERVICE ---
public static final String ACTION_ADD_USER = "userService.addUser";
public static final String ACTION_REMOVE_USER = "userService.removeUser";
// --- EVENT SUBSCRIPTIONS OF THIS SERVICE ---
public static final String EVENT_USER_MODIFIED = "user.modified";
public static final String EVENT_CONFIG_MODIFIED = "config.modified";
// --- IMPLEMENTATIONS OF ACTIONS ---
@Name(ACTION_ADD_USER)
Action addUser = ctx -> {
String name = ctx.params.get(FIELD_NAME, "");
int age = ctx.params.get(FIELD_AGE, 0);
double balance = ctx.params.get(FIELD_BALANCE, 0d);
boolean isVip = ctx.params.get(FIELD_VIP, false);
// ...
ctx.broadcast(EVENT_USER_MODIFIED, FIELD_NAME, userName, ...);
return null;
};
@Name(ACTION_REMOVE_USER)
Action removeUser = ctx -> {
String userName = "...";
ctx.broadcast(EVENT_USER_MODIFIED, FIELD_NAME, userName);
return null;
};
// --- IMPLEMENTATIONS OF LISTENERS ---
@Subscribe(EVENT_USER_MODIFIED)
Listener userModifiedListener = ctx -> {
boolean vip = ctx.params.get(FIELD_VIP, false);
// ...
ctx.call(ACTION_ADD_USER, FIELD_VIP, vip);
};
@Subscribe(EVENT_CONFIG_MODIFIED)
Listener configModifiedListener = ctx -> {
String name = ctx.params.get(FIELD_NAME, "");
};
}
# Don't repeat queries
If you need to get the same field more than once from a Tree structure,
you should rather assign it to a local variable.
The code will be more readable and the program will be faster.
So, do not use the "copy-paste" function in such cases, and instead of this...
if (ctx.params.get("addresses[0].zip", (String) null) != null &&
ctx.params.get("addresses[0].zip").asString().length() > 0 &&
ctx.params.get("addresses[0].zip").asString().startsWith("xyz")) {
store(user, ctx.params.get("addresses[0].zip").asString());
}
... write something like this:
String zip = ctx.params.get("addresses[0].zip", "");
if (!zip.isEmpty() && zip.startsWith("xyz")) {
store(user, zip);
}
# Use shorter JSON Paths
Using such long JSON Path values will consume resources unnecessarily:
String firstName = ctx.params.get("transaction.customer.personalProperties.firstName", "");
String lastName = ctx.params.get("transaction.customer.personalProperties.lastName", "");
String address = ctx.params.get("transaction.customer.personalProperties.address", "");
It is better to extract the root of the query into a separate sub-structure. The "customer" Tree is just a pointer to a sub-element of the root Tree, the following operation does not involve extra data copying or other resource intensive operation:
Tree personalProperties = ctx.params.get("transaction.customer.personalProperties");
String firstName = personalProperties.get("firstName", "");
String lastName = personalProperties.get("lastName", "");
String address = personalProperties.get("address", "");
# Cache the responses
Take some time to learn about Moleculer's caching capabilities.
Well-designed caching, using cache keys, can multiply the performance of a Service with magnitudes.
# Use local methods if possible
If a Service is definitely a local Service (always located in the same JVM),
it can also be accessed through Spring Context (eg. using the @Autowired annotation).
Local Service methods can be called directly without EventBus or Transporter.
For the most important functions,
it is worth creating "traditional" Java methods that are not "network-ready" Actions,
and can be easily called from other Services/Components without an intermediate layer.
An exception to the above is when a local Service is called through ServiceBroker for caching purposes.
# Use non-blocking APIs
Blocking is not forbidden in Moleculer, but it wastes resources anyway. If you need to access the full hardware performance, as much of the program as possible must be coded in a non-blocking manner. Unfortunately, not all backend services have a non-blocking API in Java, but if you have one, use it and don't block the Thread. If there is a non-blocking API for a backend service, it can be converted to Promise.
The following section describes how to convert various non-blocking techniques to Promise-based methods.
# Converting callback to Promise
Callback-based processing can be converted to Promise-based processing according to the following scheme.
The structure of the Callback interface is as follows:
public interface Callback {
public void onFinised(Object data);
public void onError(Throwable error);
}
And the "callbackMethod" using the Callback interface is as follows:
public void callbackMethod(Object input, Callback callback) {
ForkJoinPool.commonPool().execute(() -> {
callback.onFinised("123");
});
}
To convert it to Promise-based method,
the call must be embedded in the constructor of Promise, as follows
(this manner is similar to the ES6 Promise syntax):
public Promise promiseMethod(Object input) {
return new Promise(resolver -> {
callbackMethod(input, new Callback() {
public void onFinised(Object data) {
resolver.resolve(data);
}
public void onError(Throwable error) {
resolver.reject(error);
}
});
});
}
Hereinafter we can use the "promiseMethod" in waterfall-like processing:
Action add = ctx -> {
String input = ctx.params.get("input", "default");
// Waterfall processing of asynchronous events
return promiseMethod(input).then(rsp -> {
// ...
}).catchError(err -> {
// ...
});
};
# Converting CompletableFuture to Promise
For a consistent programming style, you should also convert frequently used CompletableFuture objects to Promise.
Example function that returns a CompletableFuture object:
public CompletableFuture<String> futureMethod(Object input) {
CompletableFuture<String> future = new CompletableFuture<String>();
ForkJoinPool.commonPool().execute(() -> {
future.complete("123"); //
});
return future;
}
To convert it to Promise-based method,
simply pass the CompletableFuture as a Promise constructor parameter:
public Promise promiseMethod(Object input) {
return new Promise(futureMethod(input));
}
If the CompletableFuture returns with a POJO object, you should convert it to a Tree object.
This way, both remote and local calls will return with the same Tree (~=JSON) object:
public Promise promiseMethod(Object input) {
return new Promise(futureMethod(input)).then(rsp -> {
User user = (User) rsp.asObject(); // Convert "User" object to serializable Tree
Tree tree = new Tree();
tree.put("id", user.getID());
tree.put("name", user.getName());
return tree;
};
}
The Promise-based function can be published for other (eg. Node.js-based) Services via Actions,
or converted directly into a REST service using the
@HttpAlias Annotation:
@HttpAlias(method = "POST", path = "api/action")
Action action = ctx -> {
return promiseMethod(ctx.params);
};